@misc{gao2026spatialworldbenchmarkinginteractivespatial,
title={SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks},
author={Hongcheng Gao and Hailong Qu and Jingyi Tang and Jiahao Wang and Zihao Huang and Hengkang Qiao and Shihong Huang and Junming Yang and Yi Li and Hongyixuan Yuan and Wenjie Li and Bohan Zeng and Wenbo Li and Bo Wang and Jianhui Liu and Olive Huang and Haoyang Huang and Wentao Zhang and Guoqing Huang and Nan Duan and Yinpeng Dong},
year={2026},
eprint={2606.09669},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2606.09669}
}Benchmark Overview
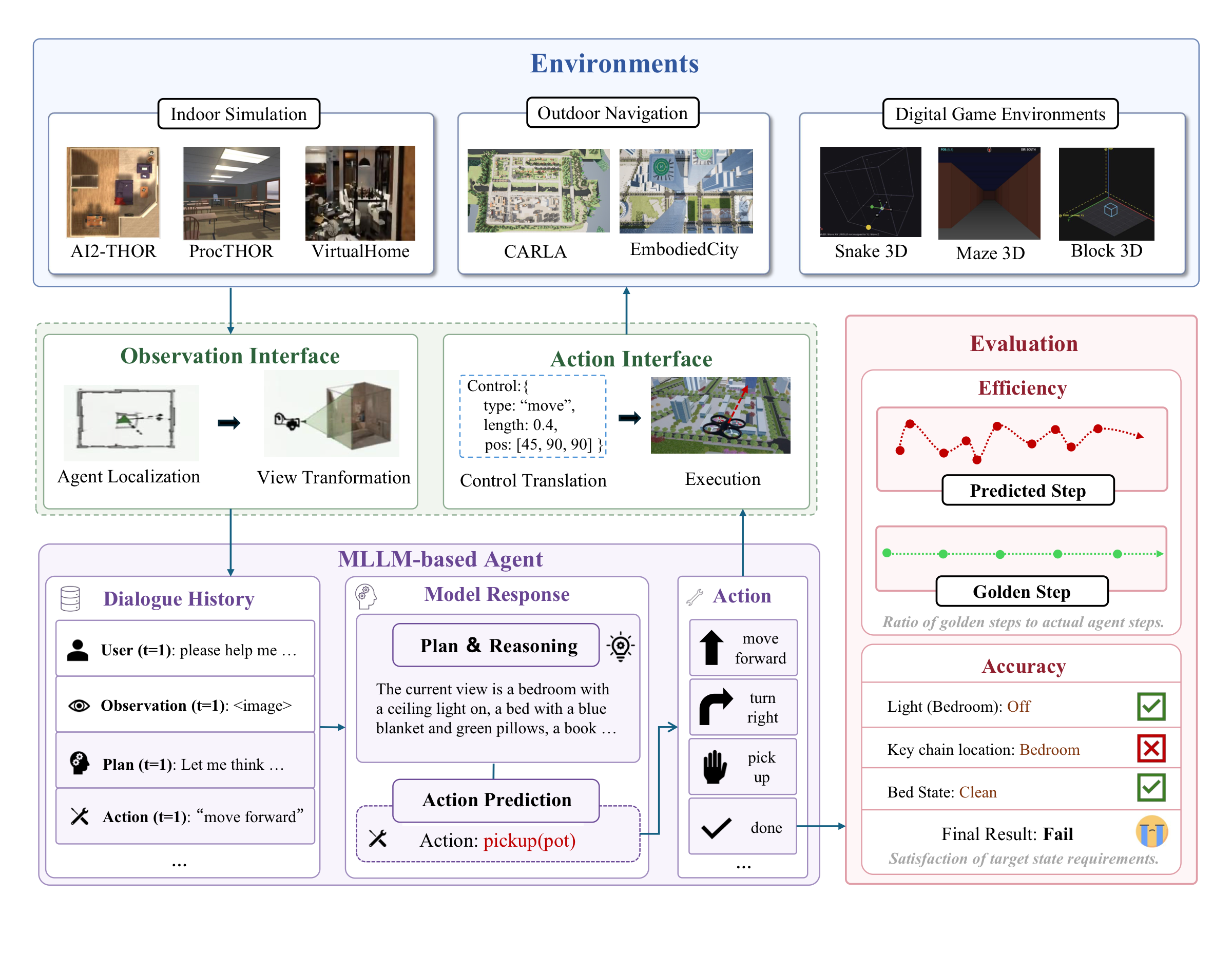
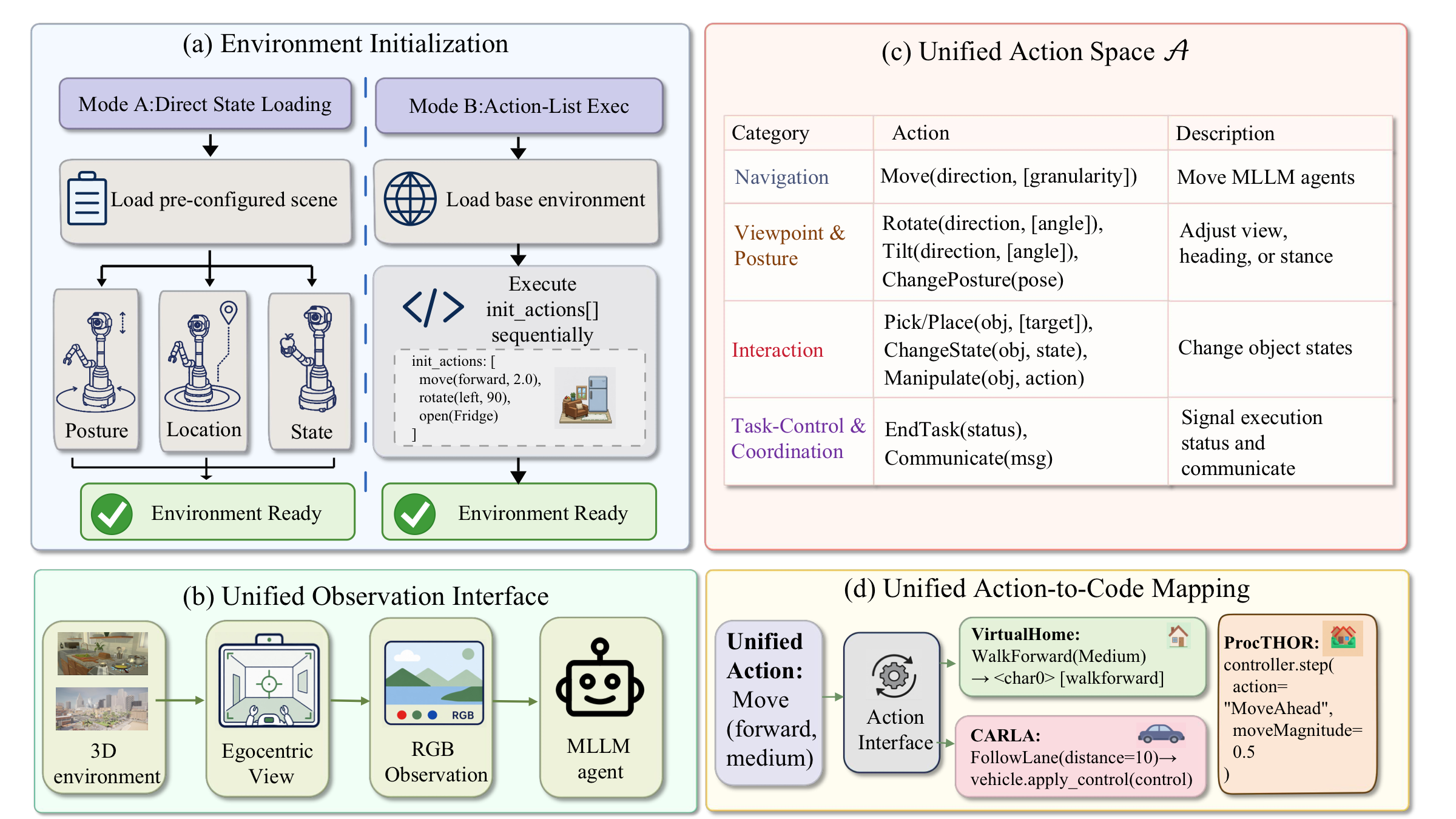
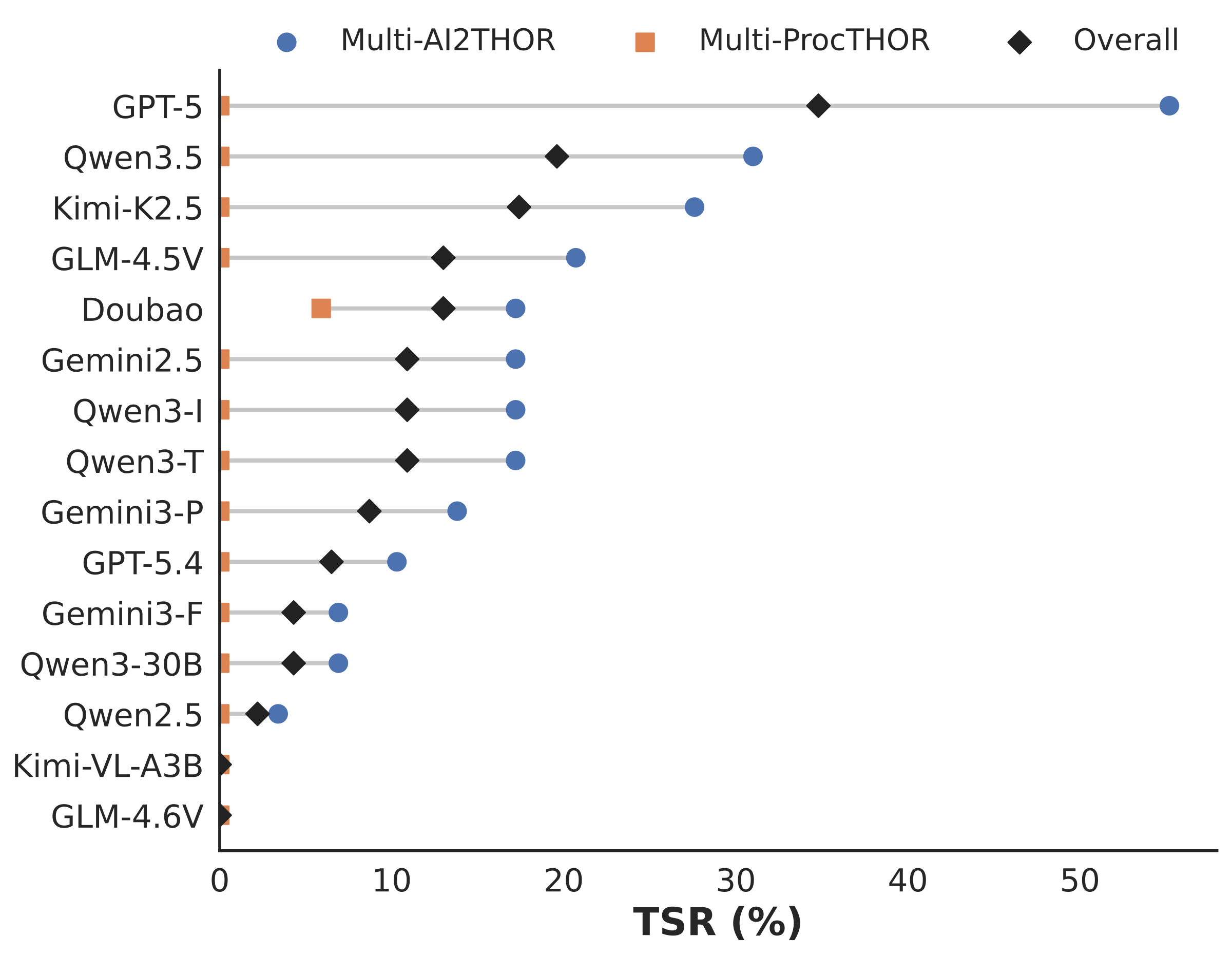
SpatialWorld is a scalable, general-purpose evaluation framework for multimodal agents, supporting end-to-end task solving and structured plan generation. It unifies diverse 3D backends under a standardized observation-action interface, enabling rigorous assessment of interactive spatial reasoning via reproducible benchmarks and automated efficiency metrics.
The benchmark wraps eight heterogeneous simulation backends behind a shared closed-loop protocol: agents receive only a natural-language instruction and egocentric RGB observations, express decisions through a unified text-based action interface, and are evaluated with human-validated terminal-state verifiers.
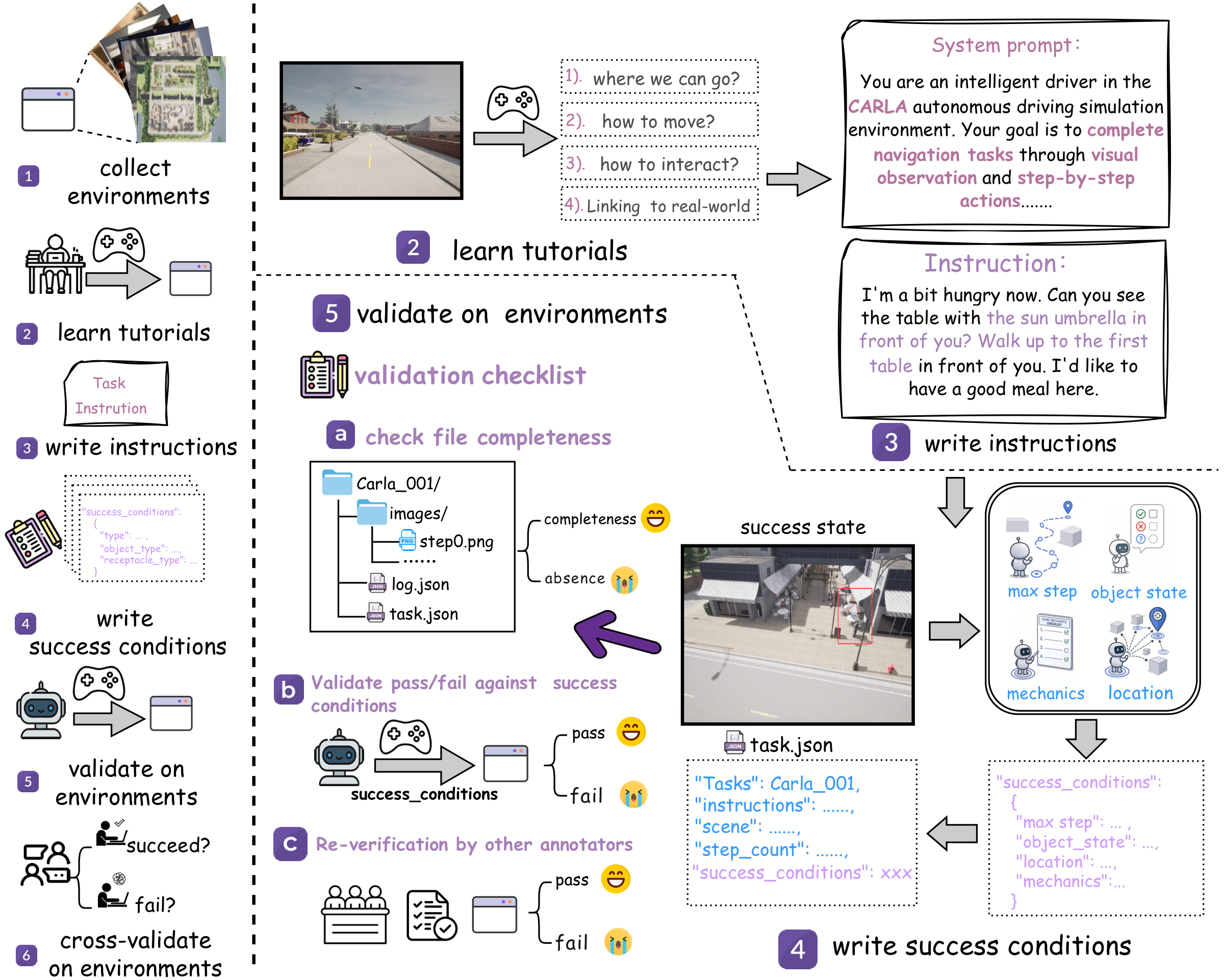
Task construction follows a unified pipeline across all environments: collect environments, write instructions, define success conditions, and validate trajectories through automated execution checks and human review.
Scroll vertically to view figures